
第二日・TETRADによる実習
第二日目はTETRADというコンピュータソフトウエアを使って授業が行われた。
初めにTETRADについての紹介と使い方の説明を受けた後、実際に与えられたデータをTETRADを使って分析し、データを説明する因果的モデルを特定・検証する作業を行った。これを通して、データからモデルを構築するという、科学において頻繁に行われている作業を理解し、またその際に生じる問題を理解することを目指した。
私たちの主眼は、このような授業を実際に受けてみることで、統計的手法や科学的モデル形成の分析からどのような科学哲学的知見が得られるのか、また、このような授業が科学哲学教育、特に理系の学生に対する科学哲学教育にどのように役立つかを知ることにあった。


TETRADについて
TETRADとは、カーネギーメロン大学哲学科の研究者らが開発にあたっている、因果的・統計的モデルの発見、分析のためのソフトウエアである。今回の授業ではTETRAD Ⅳ安定版を使用した。
TETRADでは、統計データからそれを説明する因果的・統計的モデルを発見したり、それらのモデルの検定、およびモデルからデータを予測することなどが可能である。得られたモデルはグラフ理論の図によって視覚的に表示することができる。
TETRADの一つの特徴は、操作が視覚的で簡単なことである。統計学やデータ分析およびプログラミングの手法に精通していない人でも、視覚的直観的操作によって、比較的簡単に作業を進めることができる。
作業の内容
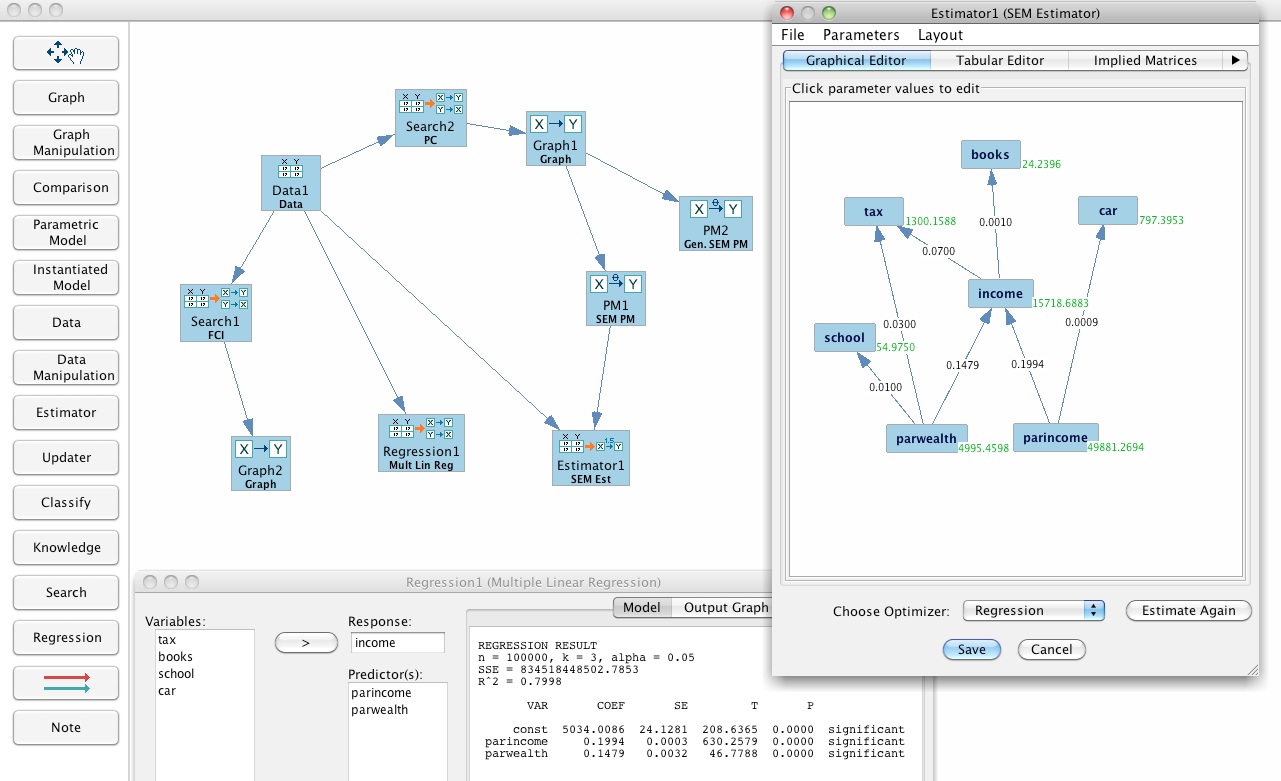
授業では、実際に7つの変数(両親の所得、両親の財産、本人の所得、学費、自動車、税金、本代)に関するデータセットが与えられ、それらの変数の間の真の因果関係を表すモデルを抽出できるかという形で授業が進められた。
TETRADにおいては、最初にモデル選択をコンピュータが行う際に、モデルがどのような形となるかについて使用者がある程度の指定を行う(背後に隠れた共通原因があるかどうかなど)。このため、分析を行う際に変数間の因果的構造について多くの正しい知識を持っていれば正しいモデルを得ることができるが、そうでない場合には、変数間の関係を捉え切れない場合も生じてくる。授業では、実際に同じデータセットに対して、異なる条件を指定して分析を行い、結果に違いが生じてくることなどを確認した。また、1000人ずつ平均化されたデータを分析し、標本の取り方によっては真の構造的関係が捉えられなくなるという問題などが紹介された。<下の画面は、データセットからの作業進行図(左上)と予測的な因果構造に基づく回帰分析結果(右・下)>
考察・感想
TETRADでは、科学的研究活動において広く行われているような、データ分析によるモデル構築の作業を、ある程度制約はあるものの、専門家でない人々にも比較的解り易い形で行うことができ、またその際に生じる様々な問題点を浮かび上がらせ、検討できることがわかった。操作の簡単さと、結果が視覚的に表示されることがTETRADの強みだろう。今回の授業で行ったように、一般のデータ分析に関する諸問題や、科学哲学的に問題となるトピックを扱うことも可能である。したがって、理系学生のみならず、文系の学生などに対しても、統計・データ分析や科学哲学に関する一部のトピックを紹介する手段として大変有効であると考えられる。特に、社会科学や生物学など統計的手法を多用する分野の学生や、あるいは経済学の哲学、生物学の哲学など、それらの分野の哲学に関心のある学生には、入門段階などで効果的な授業を行えば、興味を持ち役立てて貰うことができるのではないか。
一方、授業の最後の質疑応答の際にも話題となったが、理論物理など、データからモデルを構築するという科学観には比較的馴染みにくいと思われる分野もあり、そういった分野の学生に今回のような形での授業がどの程度受け入れられるかについては疑問の余地が残った。しかし、一般にデータ分析に関する知識は、現代社会を生きていく上でどのような分野の学生にとっても役立つと考えられる。TETRADは、そのような統計・データ分析の教材の一つとしても、従来の統計・データ分析の授業とは違った新しい視点からの授業を提供できる可能性があると思った。 (佐藤・記)